 by
by 
TABLE OF CONTENTS
In this article, I’m going to walk you through everything you need to know about GPU core clocks and GPU memory clocks.
An understanding of these specifications will help you when shopping for a graphics card, especially when you’re choosing between different manufacturer’s versions of the same GPU.
What Are GPU Cores?
GPU cores are responsible for the bulk of the processing that your graphics card is doing.
Like with CPU cores, the underlying architecture of the core will have a much bigger impact on performance than just what it happens to be clocked at or how many there are.

Following the CPU example for a moment, let’s say you have two 4-core Intel CPUs that run at 3.6 GHz to choose from.
If you only look at the base level specs, that’s going to be a more difficult choice to make, since the apparent difference simply isn’t present on a surface level.
What you do in this situation is determine which of your options is using a better, more up-to-date CPU architecture that will get more performance out of those 4 cores running at 3.6 GHz.
If both are using the same architecture in the same generation, it could also be a case of choosing whether or not to have certain features (like integrated graphics).
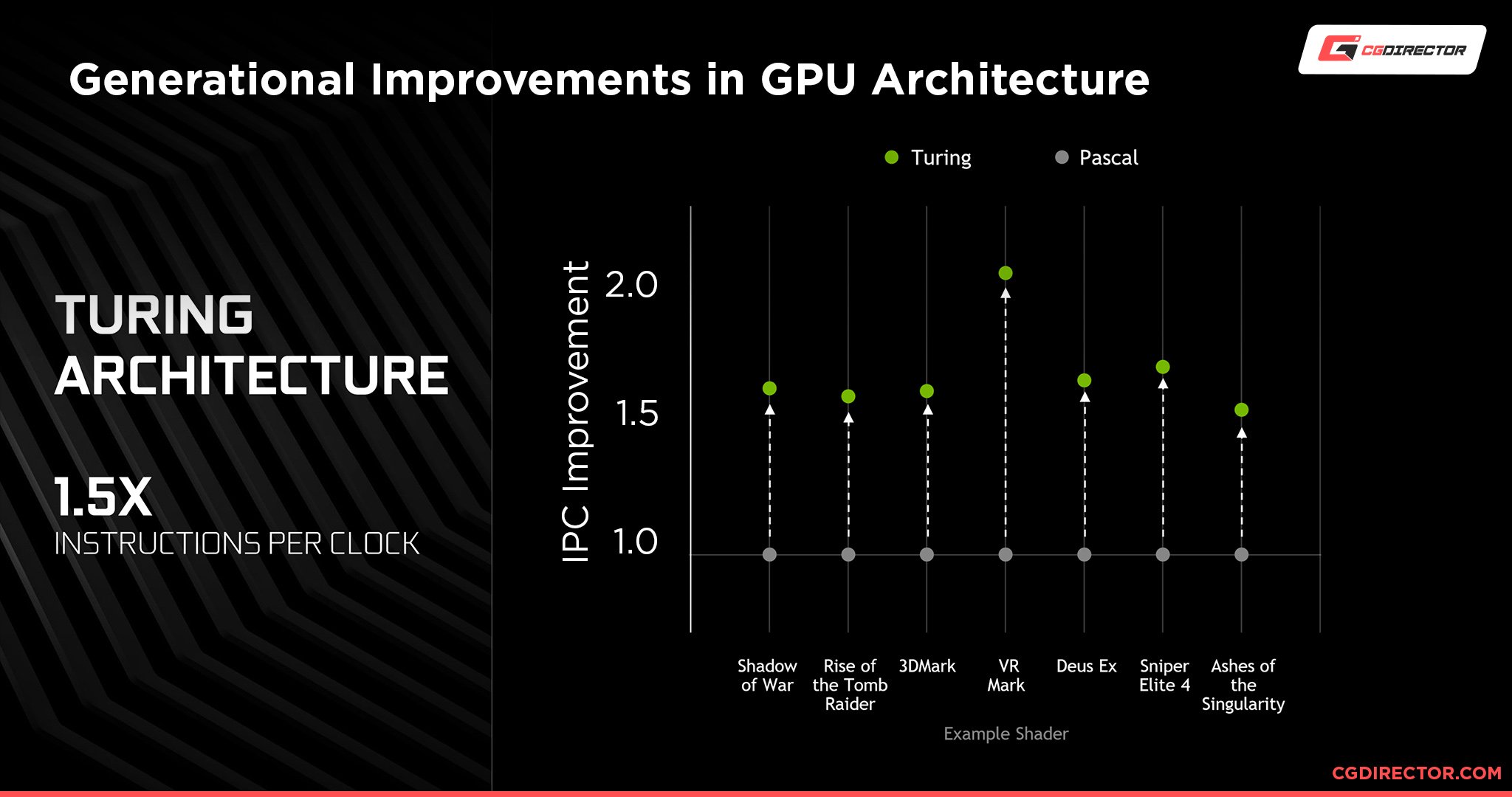
Like CPU cores, GPU cores are heavily tied to their architecture when it comes to the performance you can expect.
For example, let’s compare the GTX 760 to its successor, the GTX 960.
These are fairly similar cards in terms of specs like CUDA core count, GPU core clock, and VRAM. The GTX 760 has 1024 CUDA cores, whereas the GTX 960 has 1152 CUDA cores. Both have 2GB of GDDR5 VRAM.
The GTX760 boosts up to 1033 MHz, while the GTX960 boosts up to 1178 MHz.
Based on specs like that, you may be led to believe that they perform fairly similarly, with a marginal difference in favor of the GTX960…but that generational shift means a change in architecture, which means a much bigger change in performance levels.
The overall boost in performance from the GTX 760 to the GTX 960 is about twenty percent overall.
And that performance improvement didn’t come from adding twenty percent more cores or twenty percent more memory or twenty percent higher clock speeds: it came from fundamental improvements to the underlying GPU architecture.
Of course, the 960 is still better than the 760 in these specs, but not by as large a number as the actual performance improvement.
So, GPU cores are a lot like CPU cores but tend to come in the hundreds or thousands rather than couples or triplets.
Also like CPU cores, GPU cores are more reliant on their underlying architecture for performance improvements than raw clock speeds or core counts. With this understanding in place, it’ll be a lot easier to break down how GPU core clocks work below.
What Is GPU Memory?
Before defining GPU memory, let’s define regular memory first.

In this context, memory refers to RAM (Random Access Memory) that is used by a CPU as a volatile cache for whatever is currently being run on your system.
RAM is also called dynamic memory because of this, whereas something like your hard drive or SSD is called static memory since it isn’t so directly tied to your processing workload.
However, most GPUs don’t use standard RAM, like CPUs do. Instead, they use VRAM (Video Random Access Memory), which is exactly what it sounds like.
VRAM is much different from the RAM that’s being used by your CPU, and it doesn’t function in quite the same way as regular RAM does.
Instead of being used to juggle multiple tasks on your PC, VRAM is solely dedicated to whatever your GPU is focused on, whether that’s rendering in professional workloads or gaming.
How GPU Core Clocks Impact Performance
Between GPU core clocks and GPU memory clocks, GPU core clocks definitely have a more significant impact on performance.

Increasing your GPU core clock speed is essentially the same principle as increasing a CPU’s clock speed- by increasing the speed of operations per second, you can get a performance improvement.
However, raising your clock speed by 5%, for instance, won’t necessarily guarantee a 5% performance improvement.
As outlined earlier, there’s a lot more going on inside of a graphics card than just raw core count or the speed at which those cores are running.
Even so, GPU core clocks have the most direct impact on increasing a GPU’s performance.
So if you want to improve your in-game framerate or reduce your render times, GPU core clock is definitely the more important specification. But what about GPU memory clock?
How GPU Memory Clocks Impact Performance
GPU memory clock is a little weird.
There are times when prioritizing this specification can have a positive impact on performance, and other times where it seemingly doesn’t matter at all.
This isn’t too far removed from how regular RAM works, since a lot of users can’t seem to tell the difference between running low and high-speed RAM kits across many workloads.
Before discussing GPU memory clock specifically, we need to re-focus on GPU memory itself, or VRAM.
VRAM is basically responsible for holding all of the data that your graphics card needs for rendering a particular scene, whether that’s your favorite map in Counter-Strike or a Blender animation.
If you don’t have enough VRAM to hold all of that information where it’s easily accessible to your GPU, you’ll either crash or (more likely) start eating into your PC’s RAM. And unfortunately, your PC’s RAM is going to be significantly slower, resulting in performance loss when this occurs.

Besides raw capacity, VRAM is also closely tied to resolution and texture fidelity, especially in games.
With a graphics card using 4GB of VRAM or under, playing something at 1080p with high textures should be pretty viable. Where you may start running into issues is if you want to run the same game at 1440p or 4K.
Even if your GPU cores have the raw computational power to handle higher settings, limited VRAM can reduce performance in these scenarios significantly since anything the GPU does, needs to go through VRAM before it’s displayed on your screen.
There are two main solutions to VRAM-related bottlenecks. The ideal solution is to just throw more VRAM at it, but that isn’t always a possibility, especially in the era of chip shortages.
Another solution is to increase the speed at which that VRAM is running, also known as, overclocking your GPU memory clock.
Basically, improving GPU memory clock will only help you in scenarios where your memory bandwidth was the bottleneck, and it usually is not. And while it can help, it still isn’t a substitute for having enough VRAM, to begin with.
To learn more about GPU Memory, click here for Alex’s detailed guide on VRAM and how much of it you need for your workloads.
How Do You Compare GPU Core and GPU Memory Performance Between Different GPUs?
You don’t.
Remember what I said earlier about how both GPU and CPU cores’ performance is more determined by underlying architecture than raw clock speed or core count? This still stands, which already makes comparing GPUs across brands or architectures based on spec sheets alone extremely shaky.
CPU architecture and how it scales across a product line has more straightforward logic.
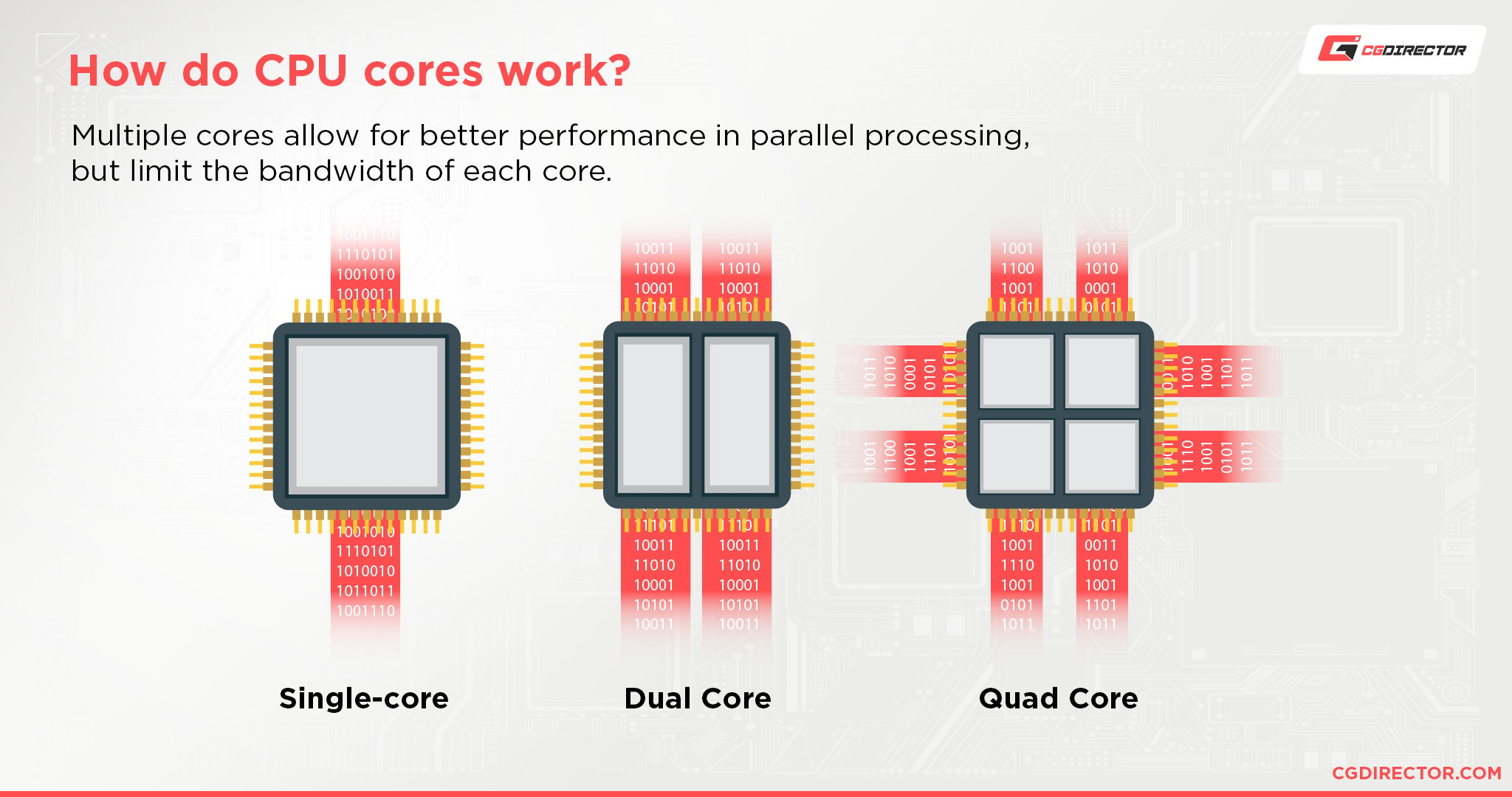
Say you’re shopping for a current-gen AMD processor, and your choices are between a quad-core and a six-core.
While the six-core is obviously better, that quad-core should still have an extremely similar level of performance in the majority of tasks.
This is because the underlying architecture is identical, so each individual core is about the same level of power. And the majority of tasks you’ll do on your PC, even a lot of gaming or active work in your Software’s viewport, is tied more to single-core performance than scaling across multiple cores.
Now for professional workloads, like rendering, that six-core is definitely going to show an improvement.
Since most rendering workloads are actually superb at scaling across multiple cores, sometimes even multiple machines, you can actually expect a 40-50% performance increase from a 50% increase in cores.
Improvements in core counts can help with games, too, provided they’re modern enough to scale across multiple cores well.
Most games, especially older ones, are not well-suited for this, though, so we wouldn’t recommend that a gamer goes out of their way to have as many cores as possible unless they’re looking to do more than just game on their PC.
Now, you have a rough understanding of how CPU architecture works.
So, what makes GPU architecture so different?
Basically, GPU cores are already made to function as a cohesive, single unit in a way that CPU cores are not.
So, you aren’t going to experience similar performance to a GTX 1070 on a GTX 1060 in any workload, because despite the underlying architecture being identical, the raw bump in core count and other specs makes the GTX 1070 objectively better in every possible scenario.
There are no GPU-based applications that are tied to a single core in the way that CPU-based applications often are, so scaling the same architecture doesn’t work in quite the same way that it does with CPUs.
Now, this isn’t to say that you shouldn’t compare GPU specs. If they’re using the same underlying architecture, you can still get some ideas of what’s happening under the hood by looking at spec sheets.
But you’ll want to go beyond just GPU core and GPU memory cores/clocks, because higher-end GPUs will also do things like increase the amount of VRAM, or the bandwidth available to that VRAM.
The best way to compare different graphics cards isn’t by looking at spec sheets, though.
The best way to compare different graphics cards is by looking at reputable benchmarks of the software or game you’re looking to use.
How Do You Compare GPU Core and GPU Memory Performance Between Different Versions of the Same GPU?
But…
What about comparing different versions of the same GPU?
This is where comparing GPU core and GPU memory clocks actually makes a lot of sense.

If you aren’t familiar with the GPU market, you may not know that the performance of your GPU can change depending on which partner you happen to buy it from.
I’ll break it down real quick. The process goes something like this:
- The GPU manufacturer (AMD or Nvidia) manufactures the GPU. From here, they can slap their own stock cooler designs on and sell them straight to consumers, or they can instead sell the GPU to a partner.
- The GPU partner (GPU brands like MSI, EVGA, and so on) takes the GPU they purchased from the manufacturer and tweaks it. Every GPU partner will put their own cooler design on top of the GPU, and the characteristics of these designs can differ pretty greatly from brand to brand.
- In accordance with the partner’s cooler design, the partner will usually then proceed to up the clock speeds of the GPU core and GPU memory within the limitations of their own cooler design.
The end result of this process is that you get different versions of the same GPU that perform differently due to different cooling, different clocks, or both.
In these cases, comparing GPU core and GPU memory clocks between GPUs is actually pretty ideal for picking out which one will perform better, but you’ll still want benchmarks to properly quantify what improvements you’ll be seeing.
FAQ
How Much Can GPU Overclocking Actually Improve My Performance?
I would say the most you can reasonably expect from a GPU overclock is somewhere within the range of a 5-10% performance improvement.
At the end of the day, unfortunately, overclocking an RTX 3060 will not turn it into an RTX 3070, no matter how hard you try. So don’t expect GPU overclocking to be a substitute for getting a higher-end graphics card or an eventual upgrade.
However, that extra bit of performance can go a long way toward extending the lifespan of your graphics card, especially if you’re running into games that are juuuuust below playable framerates.
Can Normal RAM Be Used As VRAM?
Unless you’re using a CPU with integrated graphics, no.
If you do find yourself in a scenario where you have to use regular RAM as VRAM, be sure to opt for at least DDR4-3600 RAM in order to get some half-decent performance.
While you won’t be able to reach the same levels of performance as with a discrete GPU and dedicated GDDR RAM, you can still improve the scenario significantly by having good desktop RAM.
To learn more about using desktop RAM used as VRAM in this scenario, check out the “Memory Speed vs IGP Performance” section of this HardwareCanucks video on YouTube. The rest of the video should also be fairly enlightening for iGPU users in general.
Can VRAM Be Used Like Normal RAM?
No.
…unless you’re using a modern game console. Consoles like the PlayStation 4 and Xbox Series S use PC-based architecture and lots of GDDR RAM that is used for both graphics rendering and general memory usage.
This isn’t a thing that you can do in a regular desktop environment, though.
Is Undervolting The Same As Underclocking?
Undervolting is the process of reducing the voltage coming to a graphics card in order to reduce temperatures and hopefully stabilize performance.
Overclocking is the process of increasing clock speed in order to improve performance overall, but it necessitates increasing voltage in order to push the hardware in question to its full potential.
This will also increase temperatures, so it’s only recommended if you know what you’re doing and how to alleviate GPU temperatures in your PC.
Undervolting does not actually require you to reduce clock speeds in order to meet your goals.
If done properly, you can undervolt a GPU to achieve nearly identical performance while considerably reducing temperatures and power consumption.
In fact, you may even experience better performance, since undervolting also reduces the likelihood of thermal throttling.
Over to You
If you have any other questions about GPU core clocks or memory clocks or if this article helped you understand any concerns you might be having with GPU core clocks and memory clocks, let us know in the comments below or our forum!
![Guide to Undervolting your GPU [Step by Step]](https://www.cgdirector.com/wp-content/uploads/media/2024/04/Guide-to-Undervolting-your-GPU-Twitter-594x335.jpg "Guide to Undervolting your GPU [Step by Step]")

![Are Intel ARC GPUs Any Good? [2024 Update]](https://www.cgdirector.com/wp-content/uploads/media/2024/02/Are-Intel-ARC-GPUs-Any-Good-Twitter-594x335.jpg "Are Intel ARC GPUs Any Good? [2024 Update]")
![Graphics Card (GPU) Not Detected [How to Fix]](https://www.cgdirector.com/wp-content/uploads/media/2024/01/Graphics-Card-GPU-Not-Detected-CGDIRECTOR-Twitter-594x335.jpg "Graphics Card (GPU) Not Detected [How to Fix]")

1 comment
25 November, 2024
Probably one of the best written articles on explaining GPU clock speed on the web. Thanks for all of the work you’ve done to create this brilliantly thorough article.